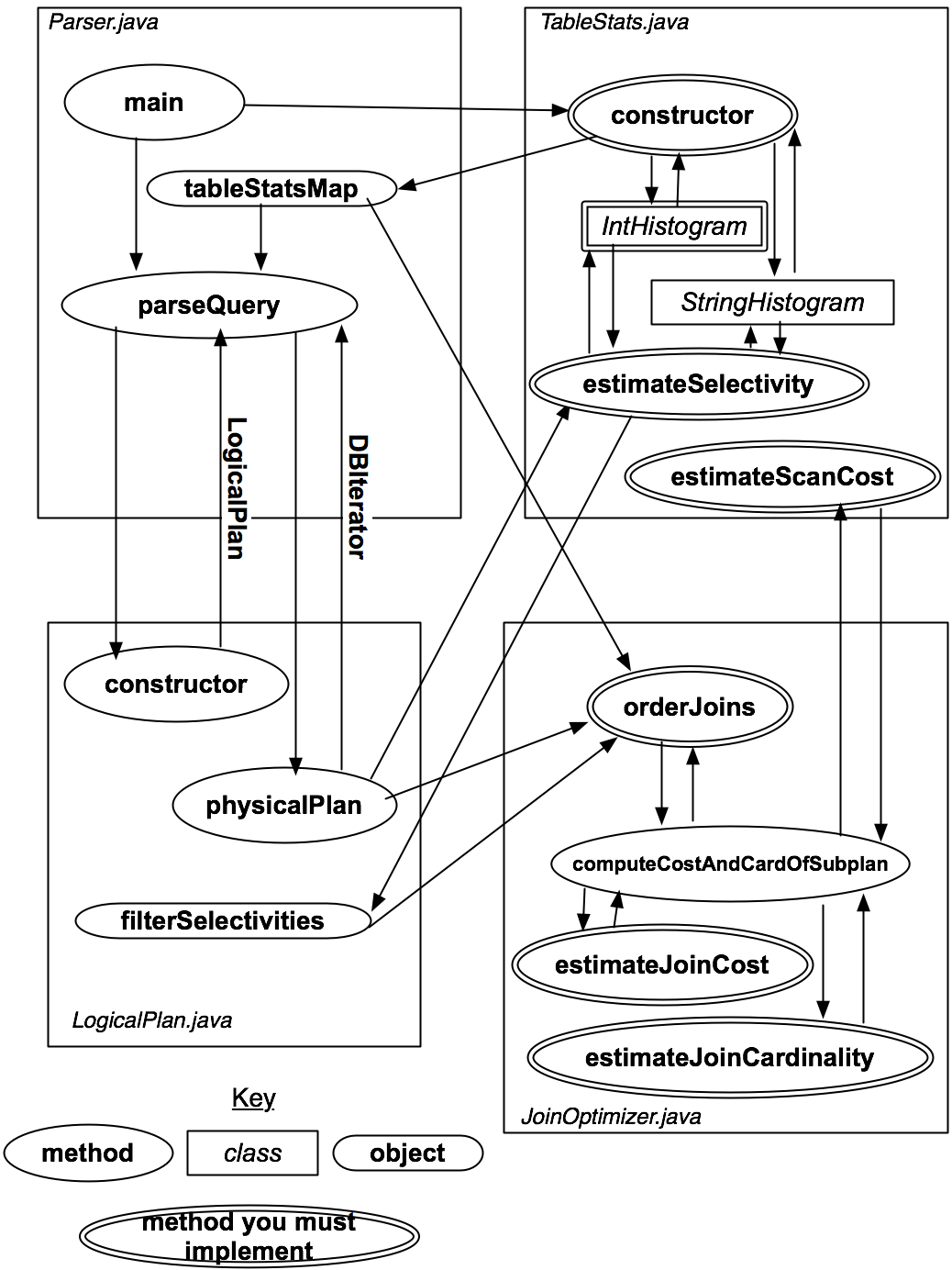
Figure 1: Diagram illustrating classes, methods, and objects used in the parser and optimizer.
Deadlines:
In this lab, you will implement a query optimizer on top of SimpleDB. The main tasks include implementing a selectivity estimation framework and a cost-based optimizer. You will be implementing something similar to the Selinger cost-based optimizer discussed in class. The remainder of this document describes what is involved in adding optimizer support and provides a basic outline of how you might add this support to your database. As with the previous labs, we recommend that you start as early as possible.
Quick jump to exercises:
Jump to Submission instructions.
You will need to add these new files to your release. The easiest way to do this is to untar the new code in the same directory as your top-level simpledb directory, as follows:
$ cp -r cs133-lab2 cs133-lab3
$ wget https://www.cs.hmc.edu/~beth/courses/cs133/lab/cs133-lab3-supplement.tar.gz
tar -xvzkf cs133-lab3-supplement.tar.gz
Now all files from lab 2 and lab 3 will be in the cs133-lab3 directory.
To work in Eclipse, create a new java project named cs133-lab3 like you did for previous labs.
You will be writing code in three Java files: IntHistogram.java, TableStats.java, and JoinOptimizer.java.
Here's a rough outline of how you can proceed with this lab.
More details on these steps are given in Section 2 below.
Before getting started with the implementation, you need to understand the overall structure of the SimpleDB optimizer.
When you run SimpleDb, it runs the main() method in Parser.java. When the Parser is invoked, it will compute statistics over all of the tables (using statistics code you will write). When a query is issued, the parser will convert the query into a logical plan representation and then call your query optimizer to generate an optimal physical query plan.
The overall control flow of the SimpleDB modules of the parser and optimizer is shown in Figure 1.
Figure 1: Diagram illustrating classes, methods, and objects used in the parser and optimizer.
The key at the bottom explains the symbols; you will implement the components with double-borders. The classes and methods you will implement will be explained in more detail in the text that follows (you may wish to refer back to this diagram), but the basic operation is as follows:
In the exercises to come, you will implement the methods that help physicalPlan devise an optimal plan.
This exercise will ask you to briefly read some of the code that formulates a physical query plan after parsing a declarative SQL query, and answer a few questions. You should include your responses in your writeup.
Skim parseQueryLogicalPlan() in Parser.java to see how a LogicalPlan object is created. You should focus mainly on reading the comments throughout this method and note to yourself when tables, joins, filters, and aggregates are added to the LogicalPlan. For seeing joins and filters added, you'll end up looking at processExpression() in Parser.java. You should also read the method descriptions for addJoin, addFilter, and addScan in LogicalPlan.java
Question 1: How many LogicalJoinNode, LogicalScanNode, and LogicalFilterNode objects would you expect to be added to the LogicalPlan if the query was:
SELECT * FROM Students S1, Students S2, Enrolled E WHERE S1.sid=E.sid AND S2.sid=E.sid AND E.cid = 133;
Question 2: The method physicalPlan() in LogicalPlan.java creates a physical query plan using the logical query plan and statistics about each table in the plan. Read through the method description. Note that the return type of physicalPlan() is DbIterator; recall that each query plan operator implements the DbIterator interface. Why does it make sense that the physical query plan is represented as a DbIterator?
Question 3: Now read physicalPlan() up until you see the call to orderJoins(). The first two while-loops iterate over the LogicalScanNodes and LogicalFilterNodes. Note the updates to the local variable filterSelectivities. After these first two while-loops, what do you expect each entry in the instance variable subPlanMap to represent? You can ignore entries that weren't added in physicalPlan(). Hint: look for the gets and puts on subplanMap.
Finally, skim the rest of physicalPlan() to get a sense of how joins and other operators are added to the plan.
p=t1 join t2 join ... tn
, which signifies a left deep join where t1 is the left-most
join (deepest in the tree).
Given a plan like p, its cost will include the I/O costs of scanning and joining each relation, as well as the CPU cost of the joins.
scancost(t1), the I/O cost of scanning table t1, is simply number_of_pages_in_t1 x SCALING_FACTOR.
scancost(t1) + ntups(t1) x scancost(t2) // IO cost for tuple-nested-loop join
+ ntups(t1) x ntups(t2) // CPU cost
Here, scancost(t1) is the I/O cost of scanning table t1 and
ntups(t1) is the number of tuples in table t1.
ntups can be directly computed for a base table by
scanning that table. However, estimating ntups for a table after one or
more selection predicates have been applied can be trickier --
this is the filter selectivity estimation problem.
The approach we will use is using equi-wdith histograms. The next two exercises will walk you through
creating and using histograms to estimate selectivity.
You will need to implement a way to record statistics used for selectivity estimation for an attribute of a relation. We have provided a skeleton class, IntHistogram that will do this. You should complete the constructor and the methods estimateSelectivity and addValue for IntHistogram; hints and details are below. You may also wish to implement the toString method to help with debugging.
Here is the approach to calculating selectivity that we discussed in class:
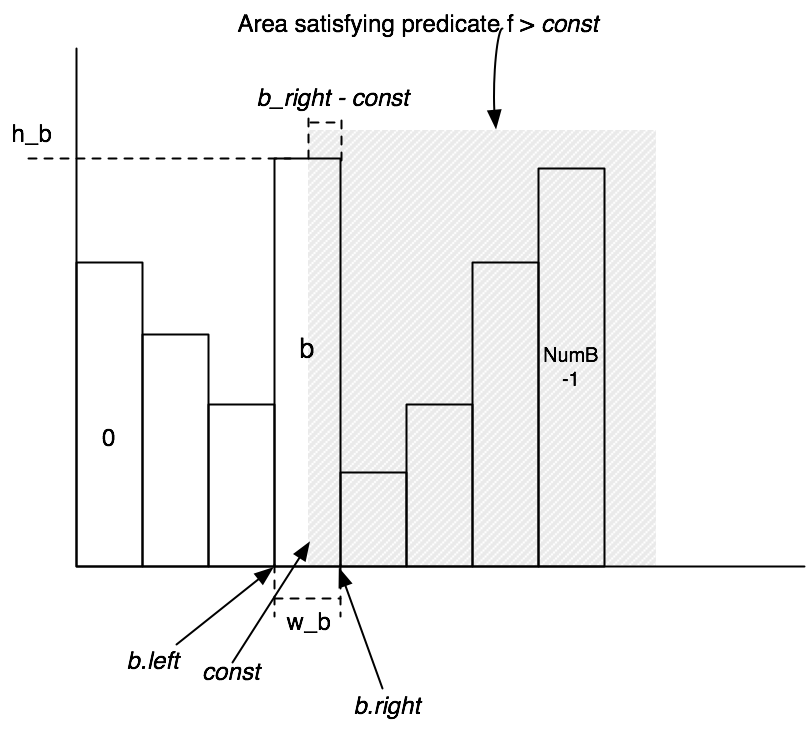
Figure 2: Diagram illustrating the histograms you will implement in Lab 3.
We have provided a class StringHistogram that uses IntHistogram to compute selectivites for String predicates. You may modify StringHistogram if you want to implement a better estimator, though you do not need to in order to complete this lab.
After completing this exercise, you should be able to pass the IntHistogramTest unit test. Note that your histogram will be more thoroughly tested after finishing Exercise 3.
The class TableStats contains methods that compute the number of tuples and pages in a table and that estimate the selectivity of predicates over the fields of that table. The query parser we have created creates one instance of TableStats per table, and passes these TableStats structures into your query optimizer.
You should fill in the following methods and classes in TableStats:To create a SeqScan to iterate over tuples in a relation with id tableid,
you will need to use a Transaction. You can do something like the following:
Transaction t = new Transaction();You will also likely make use of the classes HeapFile, TupleDesc, and Type to determine number of pages in the table, the fields of the table, and to distinguish types. Note: unfortunately, the only parent class of IntHistogram and StringHistogram is Object, so a data structure that contains both will need to have elements of type Object.
t.start();
SeqScan s = new SeqScan(t.getId(), tableid, "t");
// do stuff with s
t.commit();
After completing these tasks you should be able to pass the unit tests in TableStatsTest. Note that these tests have randomness; it is ok to fail it once every ten to twenty times you run it.
Finally, recall that the output of one join can be the input to the next join. To evaluate this expression, you need some way to estimate the size (i.e., ntups) of t1 join t2. This join cardinality estimation problem is harder than the filter selectivity estimation problem. For this lab, you can use simple heuristics such as those described below in Exercise 4.
The class JoinOptimizer.java includes all of the methods for ordering and computing costs of joins. In this exercise, you will write the methods for estimating the selectivity and cost of a join, specifically:
When implementing your simple solution, you should keep in mind the following:
After implementing these methods, you should be able to pass the unit tests in JoinOptimizerTest.java, excluding the tests that involve orderJoins.
Now that you have implemented methods for estimating costs, you will implement a Selinger-style optimizer. For these methods, note that joins are expressed as a list of join nodes (i.e., a logical join between two relations; see LogicalJoinNode.java) as opposed to a list of relations to join as described in class.
Translating the algorithm to the join node list form mentioned above, an outline in pseudocode would be as follows.
Hint: We discussed this algorithm in detail in class!
1. j = set of join nodes
2. for (i in 1...|j|): // First find best plan for single join, then for two joins, etc.
3. for s in {all length i subsets of j} // Looking at a concrete subset of joins
4. bestPlan = {} // We want to find the best plan for this concrete subset
5. for s' in {all length i-1 subsets of s}
6. subplan = optjoin(s') // Look-up in the cache the best query plan for s but with one relation missing
7. plan = best way to join (s-s') to subplan // Now find the best plan to extend s' by one join to get s
8. if (cost(plan) < cost(bestPlan))
9. bestPlan = plan // Update the best plan for computing s
10. optjoin(s) = bestPlan
11. return optjoin(j)
As an example, a size i=2 subset s of join nodes might be the two joins t1 join t2 and t3 join t1. The pseudocode in lines 4-10 would compare (1) joining t2 as the inner with t3 join t1, and (2) joining t3 as the inner with t1 join t2.
To help you implement this algorithm, we have provided several classes and methods to assist you:
private CostCard computeCostAndCardOfSubplan(HashMap<String, TableStats> stats,
HashMap<String, Double> filterSelectivities,
LogicalJoinNode joinToRemove,
Set<LogicalJoinNode> joinSet,
double bestCostSoFar,
PlanCache pc)
Given a subset of joins (joinSet), and a join to remove from this set (joinToRemove), this method computes the best way to join joinToRemove to joinSet - {joinToRemove}. It returns this best method in a CostCard object, which includes the cost, cardinality, and best join ordering (as a vector). computeCostAndCardOfSubplan may return null, if no plan can be found (because, for example, there is no linear join that is possible), or if the cost of all plans is greater than the bestCostSoFar argument. The method uses a cache of previous joins called pc (optjoin in the psuedocode above) to quickly lookup the fastest way to join joinSet - {joinToRemove}. The other arguments (stats and filterSelectivities) are passed into the orderJoins method that you must implement as a part of Exercise 4, and are explained below. This method essentially performs lines 6--8 of the psuedocode described earlier.
Note: While the original Selinger optimizer considered only left-deep plans, computeCostAndCardOfSubplan considers all linear plans.
private void printJoins(Vector<LogicalJoinNode> js,
PlanCache pc,
HashMap<String, TableStats> stats,
HashMap<String, Double> selectivities)
This method can be used to display a graphical representation of the join
costs/cardinalities (when the "explain" flag is set via
the "-explain" option to the optimizer, for example).
In JoinOptimizer.java, the orderJoins method operates on the joins class member, returning a new Vector that specifies the order in which joins should be done. Item 0 of this vector indicates the bottom-most join in a linear plan. Adjacent joins in the returned vector should share at least one field to ensure the plan is linear.
The method signature looks like this:
VectorHere stats is an object that lets you find the TableStats for a given table name that appears in the FROM list of the query. filterSelectivities allows you to find the selectivity of any predicates over a table; it is guaranteed to have one entry per table name in the FROM list. Finally, explain specifies that you should output a representation of the join order for informational purposes.orderJoins(HashMap<String, TableStats> stats, HashMap<String, Double> filterSelectivities, boolean explain)
To implement orderJoins, you can use the helper methods and classes described above. Roughly, your implementation should follow the psuedocode above, looping through subset sizes, subsets, and sub-plans of subsets, calling computeCostAndCardOfSubplan and building a PlanCache object that stores the minimal-cost way to perform each subset join.
Some things to keep in mind, particularly for using the helper methods/classes:
You have now completed the lab. Good work!
For the first deadline, you just need to submit a writeup containing your answers for Exercise 1 (you will add to this document for the remaining parts of the writeup for the final submission). For the second deadline, you should submit your code tarball so far. You can use the ant handin target to generate the tarball. For the final deadline, submit your updated writeup and final code.
You can generate the tarball by using the ant handin target. This will create a file called cs133-lab.tar.gz that you can submit. You can rename the tarball file if you want, but the filename must end in tar.gz.
The autograder won't be able to handle it if you package your code any other way!Click Lab 3 on your Gradescope dashboard. For the first deadline, upload cs133-lab.tar.gz
and writeup.txt with your responses for Exercise 1.
For the final version: click Lab 3 and then click the "Resubmit" button on the bottom of the page ; upload both cs133-lab.tar.gz and writeup.txt containing your updated writeup.
If you worked with a partner, be sure to enter them as a group member on Gradescope after uploading your files.
Your grade for the lab will be based on the final version after all exercises are complete.
Exercise 1 is 12.5% of your grade and 62.5% of your grade will be based on whether or not your code passes the test suite. Before handing in your code, you should make sure it produces no errors (passes all of the tests) from both ant test and ant systemtest.
Important: before testing, we will replace your build.xml and the entire contents of the test directory with our version of these files. This means you cannot change the format of .dat files! You should also be careful changing our APIs. You should test that your code compiles the unmodified tests. In other words, we will untar your tarball, replace the files mentioned above, compile it, and then grade it. It will look roughly like this:
[untar your tar.gz file] [replace build.xml and test] $ ant test $ ant systemtest
If any of these commands fail, we'll be unhappy, and, therefore, so will your grade.
An additional 25% of your grade will be based on the quality of your writeup, our subjective evaluation of your code, and on-time submission for the intermediate deadlines.
ENJOY!!